
Migrating from Ghost to Jekyll and Github Pages
As previously posted, I performed a migration from my prior setup, running Ghost, to this current setup using Jekyll as my content generator and hosting the site on Github Pages. This post won’t be a full technical how-to, but it will describe, at a high level, the reasoning behind the migration, a bit about my experience along the way, and some of my workflow on the new platform.
The Why
I work in IT security, so to an extent I am paid to be paranoid. I perform risk assessments where it is my job to help clients identify areas of risk within their IT operations, and I perform technical penetration testing where I get to “kick the tires” of my clients’ environments, proving areas of weakness by demonstrating real-world attacks.
With this experience in commercial environments, I also apply similar evaluations to my home network and the various toys tools that I play work with. For some time I hosted this blog in a virtual instance running within a physical server that I own, on my own Internet connection. There are various security implications present there, which always made me a bit uneasy, but I took measures to harden the system: minimizing the services running, keeping all aspects of the system (hypervisor, guest OS, software) patched, and I monitored it for strange activity. So when I discovered that the software that powered the blog had begun eating up 100% of my CPU, I grew understandably worried.
Initially, I worked to try and resolve the issue. Upon reboot, CPU usage went back down to normal, so at first I though there might have been a bug. The CPU usage returned, however. I got as far as tracing it down to the node.js process (the workhorse of the platform) but I didn’t get any further than that since by default there is no debugging available on Node. In troubleshooting the problem, I reached a state where the system would immediately use 100% CPU upon boot, with no delay (where before that, there had been some time period of the system running normally before the high utilization appeared). I found a reference that described a way to debug further, but I was faced with a decision on how to approach this situation in the context of my own personal threat model. I considered there two be two likely possibilities that would explain the CPU utilization:
- There was a bug in the version of node.js used by Ghost, which resulted in capping the CPU. I did not identify any overt malicious activity on the system, so this seemed likely.
- I had been infected by some kind of malware that targeted Ghost/Node/other libraries used on the server. Since there were no obviously harmful symptoms, a cryptocurrency miner was the most likely culprit, if it was malicious.
There were other less likely possibilities, but I focused on these two. With these in mind, my decision was pretty straight forward:
- Do I try debugging further, to understand the nature of the problem, allowing possibly malicious code to continue running, using my hardware?
- Or do I shut the system down and migrate it to a platform using only static content, reducing the attack surface and helping ensure that there is not malicious software running?
I tend to be pretty risk averse in general, but particularly where assets on my home network are concerned, I wasn’t willing to take the risk. While I did have the server running on a dedicated network segment with no access to any of my wired/wireless internal network, the layers of separation were too thin, and I was not comfortable with the service running in that condition. I shut the system down, and my blog has been offline for the past six months, while I focused on other priorities. I did save a copy of the impacted virtual instance, so there is the possibility of research at a future date to try and confirm with certainty whether the system was compromised or just encountering an unfortunate bug.
I do want to be clear that my decision to migrate away from Ghost is not meant to disparage that platform. From a features standpoint I found it to be almost everything that I was looking for. I will miss the convenience of it, but the amount of dynamic code running was just too much for me to maintain myself. As something of a yardstick, Wordpress, seemingly the most common CMS on the Internet, at the time of this writing, has over 1400 vulnerabilities listed on mitre.org:
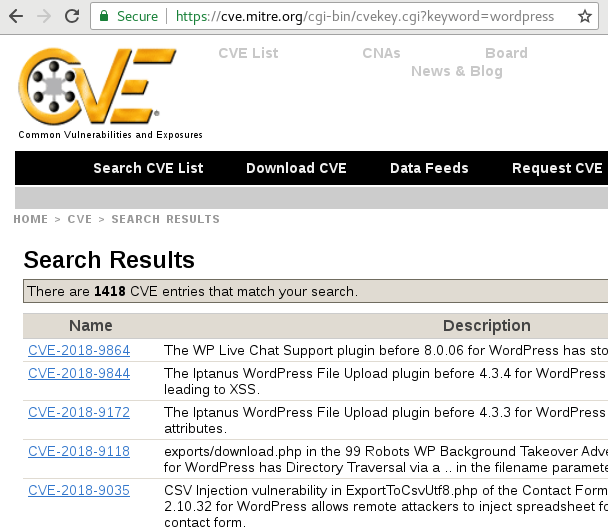
Ghost doesn’t actually come up with any vulnerabilities in such a search. Some might think this to be a good thing, but I actually consider it a worse situation: it means that nobody is finding, or at least that nobody seems to be reporting and publishing vulnerabilities on Ghost.
There is a reason I’m not in infrastructure support anymore. It’s a full time job, and I would rather focus on the content of this blog than worrying over whether or not the blog software itself has been pwned. Troy Hunt seems to share this sentiment.
The Way Here
With my decision to migrate made, I then had to answer the question of where to migrate. My various Internet searches brought me to different platforms - most of them dynamic content generators, a few static content generators - and in time I learned of the existence of Jekyll. Since Github Pages is a large part of the Jekyll ecosystem, that popped onto my radar, and I started tinkering.
I had a few false starts and some failures in just getting the combination of Jekyll + Github Pages to work, and I did not prioritize the effort enough over the last few months, resulting in extended downtime. Some of that was on me, but my failures were exacerbated by what appears to be a rather odd bug in how Jekyll handles the “description” field. OSS ftw, I’m sure it will be fixed soon.
Now What?
Now that I have everything working (with the exception of a few things), I’m learning the workflow of Jekyll, the pros and cons, and trying to optimize the overall process. My editor of choice so far is Atom, because it has native markdown preview:
I’m also using the CLI Github client, so I’ve thrown together some quick-and-dirty Bash scripts in the spirit of “If I typed it twice I should have scripted it once.” The contents of those scripts are below, and they are also included in the root folder of my Github pages repository. My general process is to run newpost.sh which creates a new draft, names it based on a title that I enter plus the date, auto-fills the header space and imports a collection of markdown references that I put together for my own reference. That list keeps changing, as I better learn markdown, but most of it was taken from here.
While I’m editing the post, the publish.sh script waits for a “y” response, upon which event it will move the draft of the identified file into the _posts folder and trigger gitsync.sh which initiates a git add, git commit, and a git push series of commands to upload the new post(s).
Automation scripts
newpost.sh
#!/bin/bash
# Set date format for filename and header
FILEDATE=$(date '+%Y-%m-%d')
HEADERDATE=$(date '+%Y-%m-%d %H:%M:%S')
# Prompt for post title
printf 'Choose a title: '
read TITLE
# Replace spaces with dashes, convert to lower, and strip non-alpha other than dashes.
URLTITLE=$(printf "$TITLE" | sed 's/ /-/g' | sed -e 's/\(.*\)/\L\1/' | sed 's/[^[:alnum:]-]//g')
# Name, create, and initialize draft file
FILEPATH="./_drafts/"
FILENAME="$FILEDATE-$URLTITLE.md"
touch "$FILEPATH$FILENAME"
printf -- "---\n" > "$FILEPATH$FILENAME"
printf "title: '$TITLE'\n" >> "$FILEPATH$FILENAME"
printf "date: '$HEADERDATE'\n" >> "$FILEPATH$FILENAME"
printf "tags: \n" >> "$FILEPATH$FILENAME"
printf -- "---\n\n" >> "$FILEPATH$FILENAME"
cat ./_drafts/YYYY-MM-DD-template.md >> "$FILEPATH$FILENAME"
# Open file for editing
atom "$FILEPATH$FILENAME"
./publish.sh
./gitsync.sh
publish.sh
#!/bin/bash
# Parse list of files in _drafts directory
for FILE in ./_drafts/*; do
# If filename begins with "20"
if [[ $FILE =~ ^./_drafts/20.* ]]; then
# Prompt user re: file
printf "Is $FILE ready to publish?\n"
printf "[y/n]: "
read ANSWER
# If file is ready, move to _posts directory
if [ $ANSWER == 'y' ]; then
mv $FILE ./_posts/
fi
fi
done
gitsync.sh
#!/bin/bash
git pull
git add --all ./_posts/ ./assets/images/
git commit -a
git push