
Intel Gathering with Canary Tokens
Reports of My Demise…
No, I’m not dead, but it turns out that changing jobs and studying for another GIAC certification and “real life” all conspire to bump blogging into the background, for me. During the recent downtime, I’ve continued slowly gathering data from the hidden href canary token that loads in this blog’s page source (described here).
I recently passed the 100 pageloads milestone so I figured it was time for everybody’s favorite pass time: data analysis.
That’s not just me, right?
Overview
Each time the hidden href gets loaded, I receive a canary token notification like this one:
One of your canarydrops was triggered.
Channel: HTTP
Time : 2019-03-16 00:23:52
Memo : vext.info hidden href
Source IP: [REDACTED]
User-agent: Barkrowler/0.9 (+http://www.exensa.com/crawl)
...
I have played with a few canary tokens but since my prior post (March of 2019), I have only had one that is out in the wild in active content: the previously mentioned hidden href token. I assumed that all the hits that have come in since March were for that remaining token… but as we will see in the analysis, that assumption was incorrect.
I never got around to setting up a proper webhook receiver for the tokens, so I’ve just been slowly collecting them via emails that land in a mail folder I set up. That necessitated a few steps to get the data in a parsable format:
- Download emails as .eml files
- Write a Python 3 script to parse each .eml file and pull out the interesting data
- Analyze the data with Excel
Step one should be self explanatory (if not, let me google that for you).
The Code
As Eric Conrad is fond of saying: if I typed it twice I should have scripted it once, so step two resulted in the below quick and dirty script:
#!/bin/python3
import os
import re
# Create a list to store results of parsing emails
scanlist = []
# Loop through all .eml files in directory and store the interesting lines into scanlist
for file in os.listdir("/path/to/your/emails/"):
if file.endswith(".eml"):
f = open(file)
scanlist.append(re.findall(r"Time : .*|Memo : .*|Source IP: .*|User-agent: .*", f.read()))
# Create an output file
o = open("/path/to/your/output.csv", "w")
# Write headers to output file (CSV)
o.write("Time" + "," + "Memo" + "," + "Source IP" + "," + "User-Agent" + "\n")
# Loop through scanlist and drop values into CSV format
for list in scanlist:
for element in list:
if re.findall("Time : .*", element):
o.write(re.findall("Time : (.*)", element)[0] + ",")
elif re.findall("Memo : .*", element):
o.write(re.findall("Memo : (.*)", element)[0] + ",")
elif re.findall("Source IP: .*", element):
o.write(re.findall("Source IP: (.*)", element)[0] + ",")
else:
o.write(re.findall("User-agent: (.*)", element)[0] + "\n")
Not efficient, but it got the job mostly done. I had to manually clean up some user-agent strings that contained commas (if you insert commas in your user-agent strings, you are an evil monster). Since there were only a few I didn’t bother updating the script to handle these edge cases.
Analysis
As soon as I threw together a pivot table for the output and started looking from different perspectives, I learned something surprising:
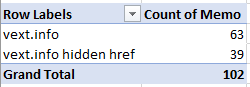
There are more instances of the retired “vext.info” token than the active “vext.info hidden ref” token. This fact surprised me, since I removed the reference to the “vext.info” token from the page source back in March when I made the last post on this subject. I can’t know exactly why the token is still being crawled, but a few possible reasons come to mind:
- Web crawlers re-visit links that they visited in the past, regardless of whether the links exist in any current content
- Web crawlers cache versions of content (a la archive.org) and periodically visit links present in older cached content
- Web crawlers scour prior versions/commit histories of Github content and visit links found there.
These are not mutually exclusive, and there might be other reasons.
With this discovery, I’ll be splitting my analysis up into the analysis of the hidden href token visits (the smaller data set) and the retired vext.info token visits.
Hidden href Token
In total, there were 39 visits to the hidden href token over the course of about five months. Among these visits, there were 14 unique user-agent strings:
- Barkrowler/0.9 (+http://www.exensa.com/crawl)
- facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)
- Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/6.0;)
- Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)
- Mozilla/5.0 (compatible; DotBot/1.1; http://www.opensiteexplorer.org/dotbot, help@moz.com)
- Mozilla/5.0 (compatible; Linux x86_64; Mail.RU_Bot/2.0; +http://go.mail.ru/help/robots)
- Mozilla/5.0 (compatible; MJ12bot/v1.4.8; http://mj12bot.com/)
- Mozilla/5.0 (compatible; Qwantify/2.4w; +https://www.qwant.com/)/2.4w
- Mozilla/5.0 (compatible; SemrushBot/3~bl; +http://www.semrush.com/bot.html)
- Mozilla/5.0 (compatible; SemrushBot/6~bl; +http://www.semrush.com/bot.html)
- Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
- Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36
- Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.8.2000 Chrome/30.0.1599.101 Safari/537.36
- Mozilla/5.0 (X11; Linux x86_64; rv:10.0) Gecko/20100101 Firefox/10.0
Nine of these strings are “friendly” in that they identify the origin, while the other five do not. Among friendlies, we see various search engines and data analytics sources:
- Exensa - Self-described as “…a very small French company specialized in large scale text data analysis..” that is creating a new search engine
- Facebook - We all know and (should) hate this big boy. Some additional thoughts on this below
- Bing - Aww, how cute. It thinks it’s a search engine!
- DotBot - An SEO company
- Mail.ru - This is fine
- MJ12bot - A business-focused data analytics service
- Qwantify - Another wannabe search engine. I didn’t realize how many of these there were these days
- SemrushBot - Another analytics company. This one has the dubious honor of being the first one that my ad blockers block at the domain level
- Googlebot - Because duh.
I manually reviewed the pages provided by each user-agent string above. Some provide information on the purpose of the crawler, while others just load the main page of the company in question. Of the descriptions I read, the most interesting to me was the blurb provided by Facebook: “Facebook allows its users to send links to interesting web content to other Facebook users. Part of how this works on the Facebook system involves the temporary display of certain images or details related to the web content, such as the title of the webpage or the embed tag of a video. Our system retrieves this information only after a user provides us with a link. You may have found this page because a Facebook user sent a link from your website to other Facebook users. If you have any questions or concerns about any links or content sent by one of our users, please contact us at legal@facebook.com.”
This is a great example of how Facebook does a lot more than they explicitly say they do. Using loose language like “such as…” in their description, they give a technically-correct description of some of the functions they perform while ignoring the fact that they do a lot more behind the scenes. It’s likely true that the reason Facebook crawled the page was that a user linked to a post that I made, I can totally buy that. However, the canary token that was triggered by Facebook was an href element with the “hidden” property set. So while Facebook might crawl “… the title of the webpage or the embed tag of a video…” they also obviously crawl other elements such as hidden href tags. There isn’t anything particularly sinister in this example, but it’s another drop in the bucket of how Facebook likes to conduct business, and it should be informative for those who read the terms of use on Facebook to get an idea of what they mean when they describe their privacy and data gathering approaches.
Back to the data, the following user-agents showed up multiple times:
- Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/6.0;): 5
- Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm): 6
- Mozilla/5.0 (compatible; DotBot/1.1; http://www.opensiteexplorer.org/dotbot, help@moz.com): 2
- Mozilla/5.0 (compatible; Linux x86_64; Mail.RU_Bot/2.0; +http://go.mail.ru/help/robots): 6
- Mozilla/5.0 (compatible; MJ12bot/v1.4.8; http://mj12bot.com/): 3
- Mozilla/5.0 (compatible; SemrushBot/3~bl; +http://www.semrush.com/bot.html): 5
- Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html): 5
The following user-agents were outliers that appeared only once each:
- Barkrowler/0.9 (+http://www.exensa.com/crawl)
- facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)
- Mozilla/5.0 (compatible; Qwantify/2.4w; +https://www.qwant.com/)/2.4w
- Mozilla/5.0 (compatible; SemrushBot/6~bl; +http://www.semrush.com/bot.html)
- Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36
- Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.8.2000 Chrome/30.0.1599.101 Safari/537.36
- Mozilla/5.0 (X11; Linux x86_64; rv:10.0) Gecko/20100101 Firefox/10.0
I performed manual lookups of the IP addresses associated with each of the five non-friendly user-agent strings, and they ended up being:
- Two instances of Iliad Entreprises, self-described as a French hosting and services provider
- An Amazon EC2 instance
- Nexeon Technologies, self-described as a US-based hosting and SaaS provider
- LeaseWeb Netherlands, a Netherlands-based hosting provider
There isn’t any real way to identify who was running the crawlers hosted out of these services.
Retired vext.info Token
In total, there were 63 visits to the retired canary token over the same five months. Among these visits, there were 8 unique user-agent strings:
- Googlebot-Image/1.0
- Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)
- Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)
- Mozilla/5.0 (compatible; MJ12bot/v1.4.8; http://mj12bot.com/)
- Mozilla/5.0 (compatible; SemrushBot/3~bl; +http://www.semrush.com/bot.html)
- Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)
- Mozilla/5.0 (compatible; YandexImages/3.0; +http://yandex.com/bots)
- Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
All of these strings are “friendly” in that they identify the origin. We again see various search engines and data analytics sources, with some overlap from the hidden href token, but a couple unique visitors:
- AhrefsBot - Another web crawler for a data analytics company trying to make a buck
- Yandex - This is fine.
The following user-agents showed up multiple times:
- Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/): 6
- Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm): 10
- Mozilla/5.0 (compatible; MJ12bot/v1.4.8; http://mj12bot.com/): 2
- Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots): 37
- Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html): 5
The following user-agents were outliers that appeared only once each:
- Googlebot-Image/1.0
- Mozilla/5.0 (compatible; SemrushBot/3~bl; +http://www.semrush.com/bot.html)
- Mozilla/5.0 (compatible; YandexImages/3.0; +http://yandex.com/bots)
Again, I want to emphasize that all of these crawlers and their numerous visits were to a link that no longer appears on any active web content on the site itself. Not necessarily sinister in any way, but I think that most folks won’t intuitively consider this kind of archived/deep crawling activity, so I think it’s a valuable lesson to learn. This is an example of the idea that nothing is ever really deleted from the internet.
Timeline Analysis across Both Tokens
One final analysis I performed was on the merged data set of both tokens to see how often various crawlers are pulling content. I found the following general patterns:
- AhrefsBot has been pulling content roughly once per month
- Bing pulled content 16 times, with 13 of them falling in the month of April
- Mail.ru pulled content 6 times, all of them in April
- Yandex had the most pulls (37), with 8 in March, 22 in April, and 7 in May
- Google pulled content 9 times in May (out of a total 10 times)
Lessons learned:
- Some crawlers continue to visit URLs that are no longer present in active content
- Putting commas in user-agent strings is evil
- In addition to their other value, canary tokens are good for gathering a list of user-agent strings to use for scripts/bots.